Quando começamos a implantar os processos de TI, uma das coisas que acontecem é a resistência dos técnicos com a questão de registro e tratamento de incidentes. Infelizmente muitos profissionais não estão preparados com o básico que é o uso do ITIL – Information Technology Infrastructure Library, Biblioteca de Infraestrutura de Tecnologia da Informação.
Com o aumento dos relatos de incidentes de segurança da informação pipocando nas time lines e feeds, o sono das equipes de TI começou a ser assombrado pela possibilidade de serem afetados por um incidente na mesma proporção. Então vamos tratar como o ITIL já orienta como atender os incidentes de segurança.
Lembrando que um incidente de segurança da informação pode ser identificado como qualquer evento adverso, confirmado ou sob suspeita, relacionado à violação à segurança de dados pessoais e empresarias, tais como acesso não autorizado, acidental ou ilícito que resulte na destruição, perda, alteração, vazamento ou ainda, qualquer forma de tratamento de dados inadequada ou ilícita.
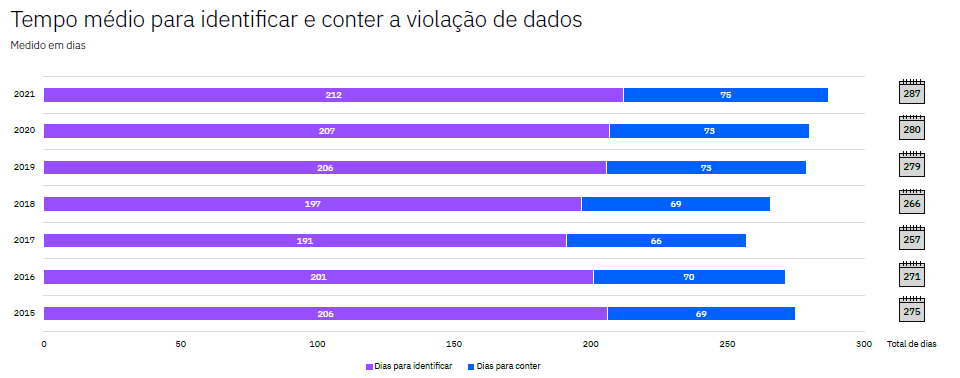
Com equipes reduzidas é difícil identificar e conter a violação de dados. Em 2021 a IBM pesquisou para o seu 17o. Relatório do Custo de uma Violação de Dados, e identificou que o tempo médio para identificação foi de 287 dias. Conforme gráfico que compartilho aqui.
Com a LGPD no art. 48 temos a determinação de que é obrigação do controlador comunicar à Autoridade Nacional de Proteção de Dados (ANPD) e ao titular a ocorrência de incidente de segurança que possa acarretar risco ou dano relevante aos titulares.
Nesse post quero explicar como os processos se encaixam no tratamento do incidente e por conseguinte atendam tanto a ANPD e demais órgãos regulatórios, quanto à organização e/ou titulares de dados pessoais. Já que não se tem tempo para trabalhar na prevenção como deveria e a cada dia mais somos surpreendidos com os incidentes.
Como Segurança da Informação é algo estratégico no nosso mundo data driven, que tal falar do papel que as boas práticas de governança tem durante todo esse processo. Lembrando que o Gerenciamento de Incidentes tem como meta reestabelecer o ambiente tecnológico, para que a empresa volte a responder as demandas de negócios o mais rápido possível. E o Gerenciamento de Problemas tem como principal objetivo descobrir a causa raiz do incidente e buscar ações de prevenção.
Vamos unir os dois em num pequeno plano de 5 fases para tratar um incidente de segurança da informação e/ou privacidade de dados:
- Detectar – fase em que se toma conhecimento por monitoramento das informações dos logs, eventos e comportamentos anormais, analisam essas informações e enviam alertas acionáveis para que a intervenção humana seja realizada.
- Responder – depois de receber o alerta, o objetivo é responder com urgência. De forma planejada, organizada e baseada em informações, por isso uma lista básica do que fazer, quem acionar, como tratar é um exercício muito válido para a TI, por mais simples que seja é melhor do que ficar como barata tonta, correndo de um lado para o outro. Sua lista de resposta a incidentes determina sua eficácia e ela deve conter ações para:
- Isolar o ambiente
- Diagnosticar o que aconteceu
- Fazer triagem do que é relevante no momento
- Determinar a urgência
- Priorizar o que abordar primeiro
- Envolver os recursos certos
- Comunicar aos stakeholders
- Corrigir – é a fase de restaurar os sistemas para a funcionalidade normal. Prever situações de interrupção do serviço, faz com que a lista do que precisa ser realizado acelere a realização das ações de contenção e correção. Lembre-se que colocar o serviço em funcionamento novamente e deixá-lo disponível para seus clientes é a prioridade principal.
- Analisar – aqui entra o Gerenciamento do Problema, quando finalmente o ambiente está no ar. É preciso obter valor do incidente, aprendendo com ele. Nessa etapa o ambiente que foi isolado, as cópias realizadas devem ser investigadas, as informações coletadas sobre o que aconteceu são reunidas (as informações são colhidas durante todo o ciclo do incidente) desde o momento que aconteceu. A busca pela causa raiz é feita com as perguntas certas e para responde-las é preciso das informações.
Vou novamente lembrar que o controlador tem que comunicar à Autoridade Nacional de Proteção de Dados (ANPD) e ao titular a ocorrência de incidente de segurança. Para isso são dados 2 (dois) dias ao Encarregado para fazer a notificação. Então na fase de análise não esqueçam de registrar:
Informações sobre o incidente de segurança e se envolve dados pessoais. A maioria dos incidentes de segurança acabam afetando dados pessoais, nem que seja a dos administradores de sistemas
- Data e hora da detecção do incidente.
- Data e hora do incidente e sua duração.
- Circunstâncias em que ocorreu a violação de segurança de dados pessoais, por exemplo, perda, roubo, cópia, vazamento, dentre outros. Os casos de vazamento de dados associados a incidentes de segurança da informação são confirmados após alguns dias do incidente. Então ações de monitoração na Web e Deep Web devem ser implementadas.
- Descrição dos dados pessoais e informações afetadas, como natureza e conteúdo dos dados pessoais, categoria e quantidade de dados e de titulares afetados nos casos de dados pessoais. Esse ponto vai ser importante nos esclarecimentos solicitados pelos titulares.
- Resumo do incidente de segurança envolvendo dados pessoais, com indicação da localização física e meio de armazenamento.
- Possíveis consequências e efeitos negativos sobre os titulares dos dados afetados.
- Medidas de segurança, técnicas e administrativas preventivas tomadas pelo controlador de acordo com a LGPD.
- Resumo das medidas implementadas até o momento para controlar os possíveis danos.
- Caso aplicável, possíveis problemas de natureza transfronteiriça.
- Outras informações úteis às pessoas afetadas para proteger seus dados ou prevenir possíveis danos.
- Prevenir – todas as lições aprendidas na fase de análise devem ser incorporadas as operações, em muitos casos isso pode significar todo um projeto de adequação de processos, soluções, monitoramento e até desenvolvimentos. Enfim todas as ações que prevenirem incidentes futuros deverão ser levantados nesta fase, vou deixar aqui algumas perguntas que podem ser revistas e consideradas nessa etapa:
- Quando o incidente foi detectado pela primeira vez? Foi executado algum roteiro de testes para se certificar que era um incidente de SI? Quanto tempo depois o escalonamento aconteceu?
- Como se descobriu o incidente? Foi o sistema de monitoramento alertou sobre o incidente? Ou foi por reclamações dos clientes internos e/ou externos?
- Quem precisa ser notificado ou quem mais está ciente do incidente? Alguma habilidade ou conhecimento foi requerido e não tinha sido previsto? Todos sabiam o suas funções na sala de guerra?
- Se houve notificações a titulares de dados, o que (se houver algo) está sendo feito sobre ele? As comunicações foram adequadas aos stakeholders?
- Quão grave o incidente é? Qual a extensão dos dados afetados?
Quem faz parte do time de Gerenciamento de Incidentes?
É essencial ter um bom plano, mas um plano é inútil sem pessoas que o executem. E essa é uma pergunta bem frequente que recebo por parte das equipes, alunos e profissionais de TI que me escrevem. Quem eu coloco na “sala de guerra”?
Vou te ajudar com um exercício simples para que você crie uma lista de participantes, que possuem conhecimento técnico e habilidades de resolução de problemas. Uma dica que eu dou é: “chame as pessoas que ajudaram a definir o Plano de Continuidade dos Serviços de TI”.
Com a lista em mãos defina funções a serem assumidas por cada um deles, e especialmente quem estará orquestrando todas ações. As funções podem variar de acordo com a organização e/ou pelo tipo de incidente. E algumas delas são essenciais para que o caos não se instale, então determine quem fará:
- Responsável ou Respondente primário – geralmente é a primeira pessoa no escalonamento responsável por aquela arquitetura de solução quando um incidente ocorre. Dependendo da complexidade o respondente primário pode ser alguém de Infraestrutura e/ou de Sistemas.
- Responsável ou Respondente secundário – é o segundo no escalonamento e que atua como um backup e poderá entrar em cena se o respondente primário não estiver disponível ou se um segundo olhar for necessário. Lembre-se da máxima que quem tem um não tem nenhum, sempre crie uma estrutura em que pelo menos tenham dois profissionais para cada assunto.
- Consultores e especialistas – Essas são pessoas que têm conhecimento aprofundado sobre um aspecto específico de suas operações. Eles estarão lá se os respondedores primários e secundários precisarem escalar o problema para alguém com mais conhecimento, pode ser um colega de outro time, um fornecedor ou um mantenedor da solução por exemplo. Manter uma lista de consultores e especialistas distribuídos pelos diversos assuntos (por exemplo, banco de dados, infraestrutura de rede, aplicativos web, segurança cibernética, antivírus, firewall etc.).
- Orquestrador ou Comandante da Sala de Guerra – função importante em um incidente ou uma interrupção em larga escala que afeta muitos componentes diferentes e/ou requer coordenação entre várias equipes e sistemas diferentes. As habilidades dessa função devem ir da capacidade de manter a calma, coordenar com maestria pessoas, manter uma linha de comunicação com todos os stakeholders e ao mesmo tempo conseguir ter uma visão holística sobre tudo o que está acontecendo e de quem está fazendo o quê.
Lembro de um gerente que acompanhava a minha equipe quando algum incidente ou problema complexo surgia e precisávamos ficar até mais tarde. Ele sempre dizia que não podia codificar em nosso lugar, mas que podia pedir o lanche e barrar as pressões que o time sofria. E isso faz uma diferença significativa na moral do time e andamento das ações.
- Documentador ou Anotador – precisa documentar o incidente com o máximo possível de detalhes, tanto o que as equipes reunidas presencial quanto remotamente falaram. Transcrever o conteúdo dessas conversar é um trabalho essencial, especialmente quando tantos stakeholders estão envolvidos e são necessárias ações de contenção, correção e prevenção nos processos, e examinar essas informações mais tarde farão uma diferença significativa.
Esse trabalho deve ser realizado sem julgamento do que deve ou não ser anotado, apenas capture todos os dados possíveis do que cada membro da equipe está fazendo, que estão dizendo e até mesmo o que eles estão sentindo e vivenciando durante aquela operação de guerra. Se o objetivo é reduzir o tempo necessário para a recuperação de incidentes, é preciso capturar as informações desde o momento em que se tem ciência do incidente.
- Comunicador ou gerente de relações públicas – em conjunto com o Orquestrador para compartilhar informações sobre o incidente com aqueles que não estão envolvidos em trabalhar ativamente para resolver o incidente. Incluindo as áreas de negócios, outros stakeholders dentro ou fora da organização afetados ou que precisem estar cientes do que está acontecendo, bem como o status de como a resposta e a correção estão progredindo.
Em situações como essa a fórmula para as comunicações tem 3 pontos:
- O que se sabe de fato (nunca suponha nada).
- O que está sendo feito (suscintamente).
- Quando sairá o próximo retorno (em XX horas).
Quando se tem uma equipe atuando no incidente e a complexidade de recuperação do ambiente vai exigir muitas horas, ou até mesmo dias, o Orquestrador precisa definir a escala de atuação. Essa agenda deve ser planejada após as primeiras ações serem implementadas e a contenção em progresso, para se ter uma ideia da extensão dos trabalhos. Afinal não basta colocar tudo no ar e depois não ter ninguém para manter o ambiente com todos os profissionais esgotados.
A agenda de trabalho precisa ser estrategicamente definida para que os membros da equipe façam suas funções de forma eficaz e eficiente tanto quanto possível. E nesse caos o melhor modelo é o de turnos, lembram que falei do respondente primário e secundário? Eles estão ai para isso, se você tem dois profissionais por assunto, o secundário pode assumir enquanto o primário descansa.
Eu acompanho as reportagens, artigos e posts que saem a cada momento sobre incidentes que ocorreram e ocorrem. Percebo que a continuidade dos negócios está diretamente ligada ao grau de maturidade no tratamento de Segurança da Informação. E isso foi confirmado com o relatório da IBM que citei no início do post, em que o custo de recuperação também é proporcional a maturidade de segurança da informação.
E por que saber disso é importante? Porque conseguir ter uma boa resposta a incidentes de segurança da informação requer investimento e as empresas precisam ter orçamentos específicos para o tema. Não se faz segurança da informação com jeitinho, o jeitinho sai muito caro e pode quebrar uma empresa.
Esse tema é bem extenso, mas acredito que quem acompanhou até aqui o post já teve uma noção do que tem de trabalho pela frente para montar um bom processo de gerenciamento de incidentes e problemas.


